Быстрый старт: Mistral-7B On-Premise
Это руководство покажет вам, как развернуть модель вывода Mistral-7B на одном GPU A100-40GB с Compressa LLM.
GPU A100-40GB позволяет разместить Mistral-7B без квантизации.
Для примера мы будем использовать версию Mistral-7B openchat/openchat-3.5-0106.
Развертывание Compressa
Первым шагом необходимо развернуть Compressa в соответствии с инструкцией.
Предположим, что Compressa развернута на порту 8080, вы можете использовать REST API менеджера по адресу http://localhost:8080/api для загрузки и развертывания модели.
Полная информация о менеджере API доступна в инструкции
или на странице Swagger по адресу http://localhost:8080/api/docs.
Загрузка модели
Если вы развертываете Compressa в частной сети без доступа к интернету, этот шаг можно пропустить. Пожалуйста, используйте инструкцию для загрузки ресурсов перед развертыванием.
Вы можете загрузить модель, используя следующую команду curl:
curl -X 'POST' \
'http://localhost:8080/api/v1/models/add/?model_id=openchat%2Fopenchat-3.5-0106' \
-H 'accept: application/json' \
-d ''
Кроме того, можно загрузить модель напрямую со страницы Swagger, нажав Try it out:
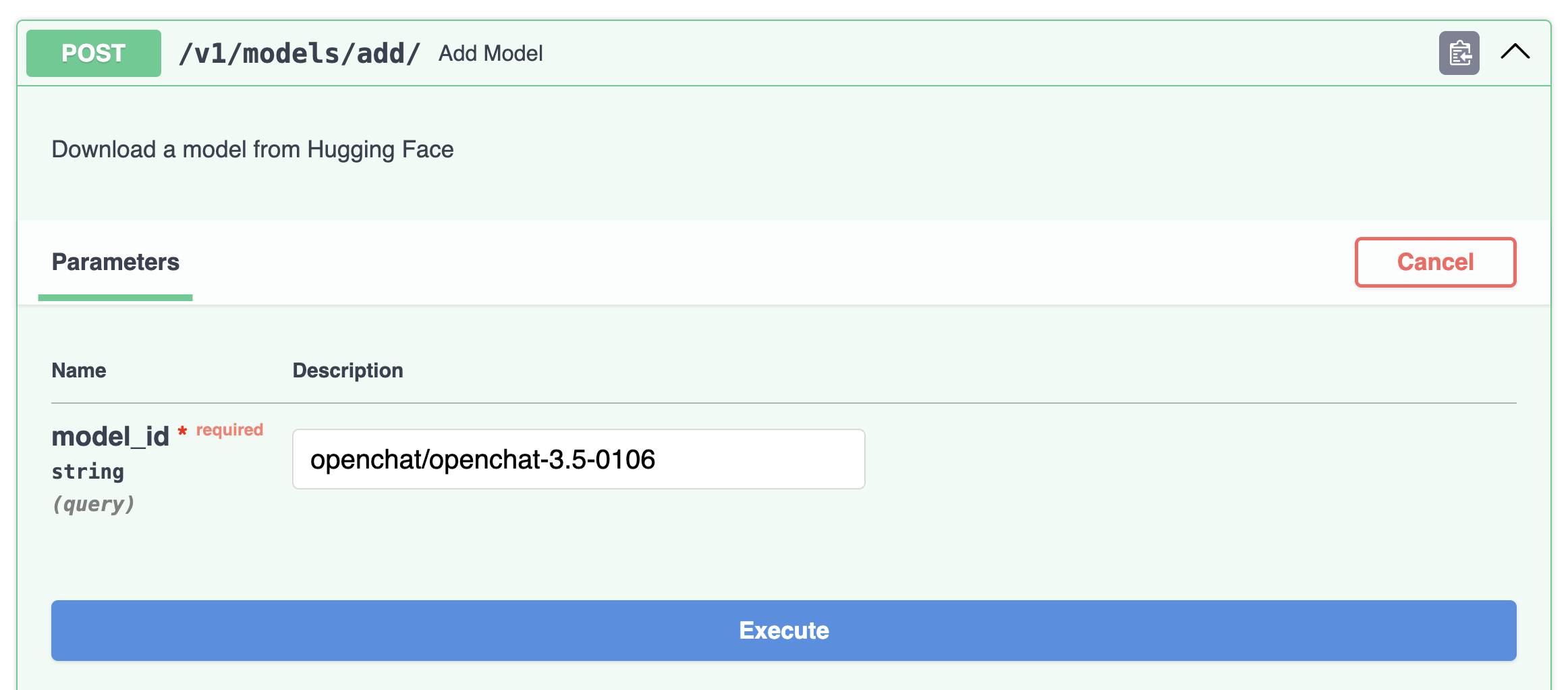
Модель будет загружена в течение нескольких минут.
Процесс можно отслеживать через лог консоли или с помощью API.
Развертывание модели
Вы также можете развернуть модель, используя следующую команду curl:
curl -X 'POST' \
'http://localhost:8080/api/v1/deploy/' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model_id": "openchat/openchat-3.5-0106"
}'
Или напрямую со страницы Swagger:
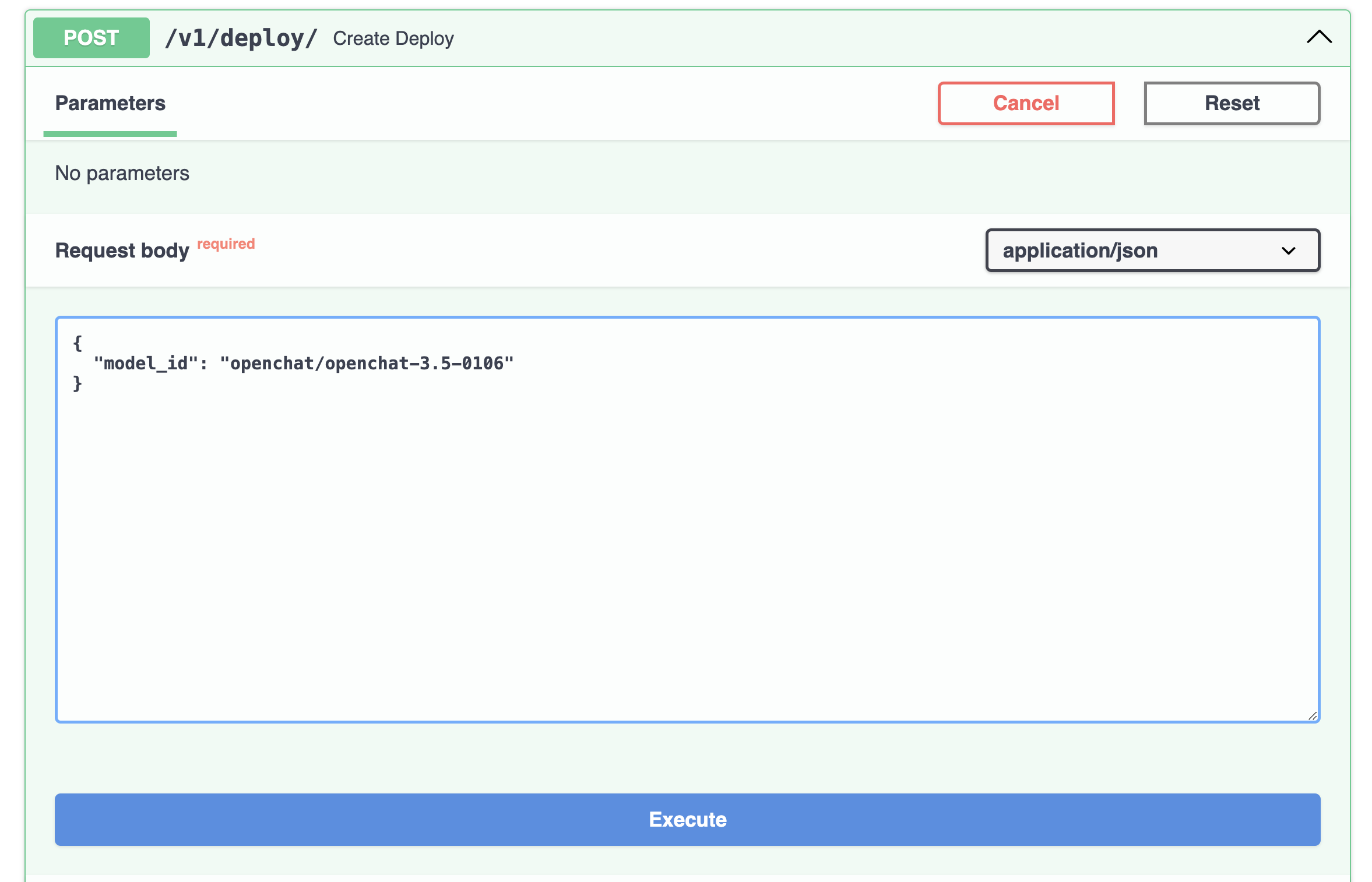
Развертывание займет менее минуты.
Доступ к модели
После развертывания модели, она будет доступна по адресу http://localhost:8080/chat:
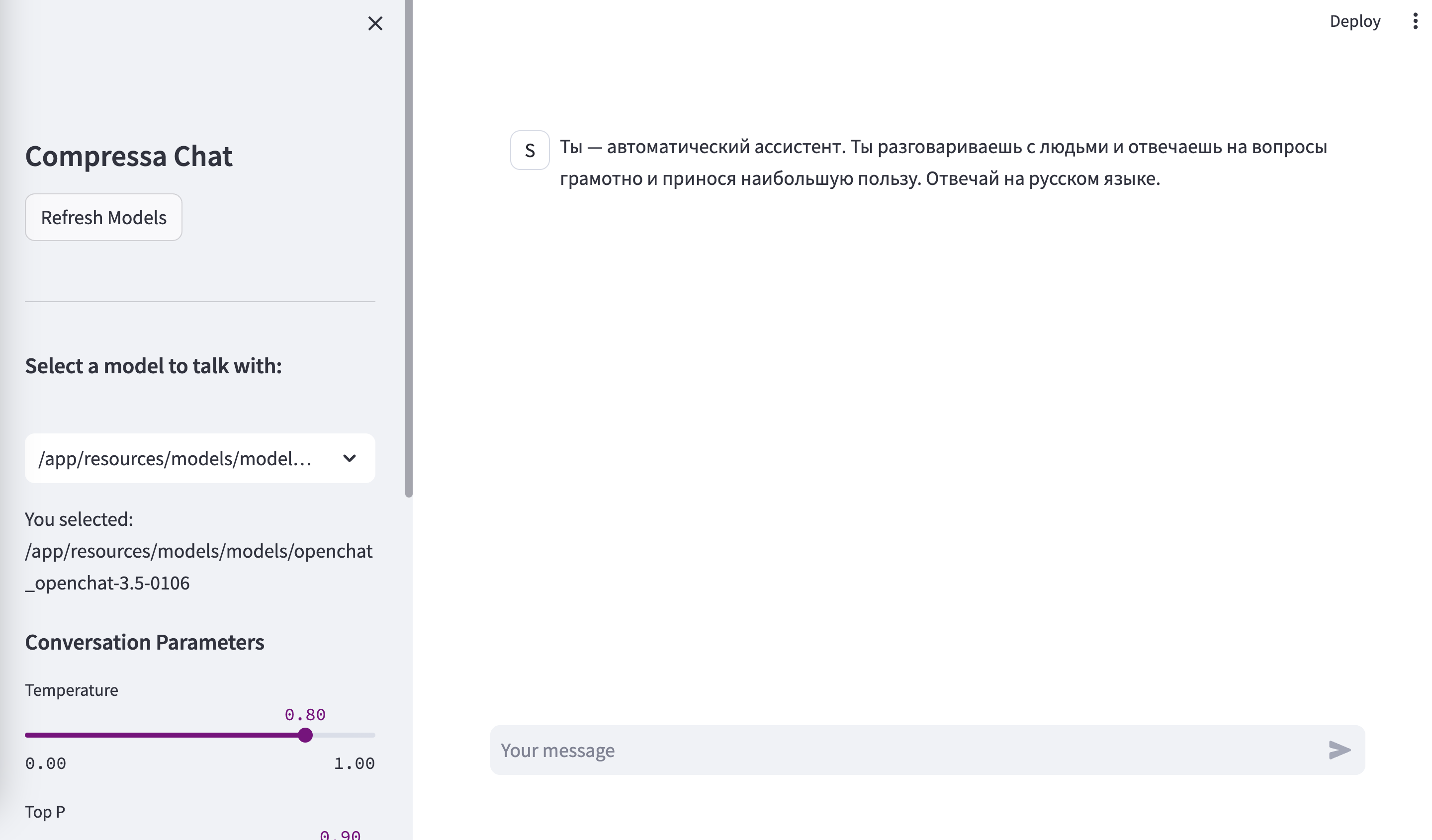
и через API, совместимый с OpenAI, по адресу http://localhost:8080/v1/completions: